Análisis, informes, datasheets…hay que leer la letra pequeña!
Publicado por davidmacia en Palo Alto Networks el 11 marzo, 2013
En el mercado del Firewalling, como en cualquier otro en realidad, la competencia es increíble, y sana. Fuerza a todos a esforzarse, a seguir luchando por tener el mejor producto, y eso nos beneficia a todos.
Esa competencia también hace, desgraciadamente, que se mezclen mensajes, conceptos, informes, estadísticas, para dar un mensaje a veces sesgado, casi siempre partidista, en pro de los intereses personales de estos fabricantes, que anuncian grandes titulares de estos estudios, escondiendo «la letra pequeña», y magnificando lo que mejor les conviene. Los hace «populares», pero no necesariamente mejores 😉

Por poner algunos ejemplos:
- NSS Labs ha sacado su último informe, y muchos Firewalls que dicen ser NGFW lo promocionan como arma comercial contundente…Pero leyendo la letra pequeña:
- «In order to establish a secure perimeter a basic firewall must provide granular control upon the source and destination IP Addresses and ports at a minimum. Next Generation Firewalls (NGFW) will extend this to provide additional control based on application and user/group ID, but are not within the scope of this report. As firewalls will be deployed at critical points in the network the stability and reliability of a firewall is imperative. In addition it must not degrade network performance or it will never be installed.« – Conclusión: No me interesan las funcionalidades de nueva generación, entre otras cosas porque si las contemplo no podría utilizar los FWs existentes – NO TIRAN!!!!
- En el último Gartner, es interesante leer las partes de «Cautions» de los Firewalls analizados, para leer cosas como (Acme substituye al nombre comercial):
- «Acme does not have a dedicated NGFW, but instead presents its UTM product, expecting a subset of product features to be used. Acme’s marketing focus on using UTM for enterprises has persisted in what is effectively an attempt to change enterprise buying behavior. This can steer away enterprise customers. Acme also has historically defined enterprises as 500 users — about half the number used by Gartner and competitors.»
- Datasheets: Muchos fabricantes también, lanzan mensajes confusos al respecto de sus tablas de rendimientos.
- No es lo mismo tráfico real HTTP de 64 Kbytes para evaluar a los equipos, que tráfico TCP o UDP de 1512 Bytes.
- No es lo mismo analizar a L4, que a L7.
- No es lo mismo tener arquitectura hardware específica, así como CPUs específicas para cada función, que CPUs genéricas.
- …
Y así podríamos ir continuando. Es interesante ir desbrozando las peculiaridades de cada estudio, análisis, y intentar profundizar un poco mas allá de la primera piel, para poder discernir, con mas criterio, cual es el mejor producto para tu entorno, el que ganará el torneo final 😉

PALO ALTO NETWORKS: EL TIEMPO NOS DA LA RAZÓN
Publicado por davidmacia en Palo Alto Networks el 11 febrero, 2013
Hace ya unos años, en Exclusive Networks decidimos apostar por un fabricante llamado Palo Alto Networks. El nombre provocaba un poco la risa tonta, nadie los conocía, pero fieles a nuestra filosofía de empresa, que es el de apostar por aquella tecnología claramente disruptiva, nos la jugamos: Invertimos tiempo y dinero, empezamos a evangelizar, explicamos a nuestros partners las ventajas que les supondría, y como conclusión: el tiempo nos ha dado la razón.
A finales de 2011 Gartner ya posicionaba a Palo Alto Networks como líder en Enterprise Firewalling, como comenté en un post anterior.
A inicios de este 2013, recién publicado, Gartner ha sacado un nuevo update. Una imagen vale mas que mil palabras. Comparad:

Ya no solo es la distancia a nivel tecnológico que ya existía antes (este año se hace aun mas evidente), sino en cuanto a crecimiento en cuota de mercado. Gracias a todos (clientes, partners, Palo Alto Networks, Exclusive Networks) por hacerlo posible!
Arista Networks, Laboratorio: vEOS y CloudVision para empezar a jugar
Publicado por davidmacia en Arista el 2 diciembre, 2012
En posts anteriores he realizado un repaso teórico de la increíble tecnología de Arista Networks: No sólo tienen los mejores switches de Datacenter del mercado, sino que ademas tienen un sistema operativo de red tan potente y flexible, que permite hacer cosas como las que a continuación comento en los siguientes pasos:
- Crea tu entorno virtual con vEOS (imagen de EOS, el sistema operativo de red de Arista, para maquinas virtuales). En el siguiente enlace está la guia paso a paso para crear, en cualquier portátil, un entorno de red de 4 switches virtuales hablando OSPF, y lo que se quiera simular: https://eos.aristanetworks.com/2012/11/veos-and-virtualbox/. Algunas imágenes de muestra del entorno:
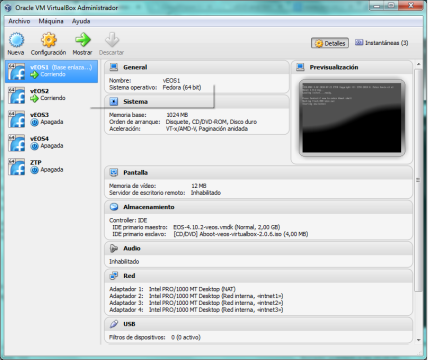
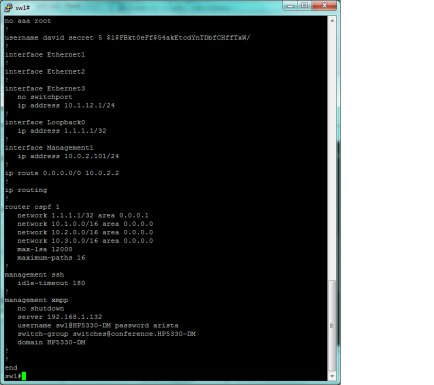
- Carga en este entorno virtual, la extensión CloudVision, que permite, habilitando un cliente XMPP en cada switch, gestionar de forma segura miles y miles de equipos de manera fácil y rápida. En el siguiente enlace se muestra como: https://eos.aristanetworks.com/2011/08/management-over-xmpp/
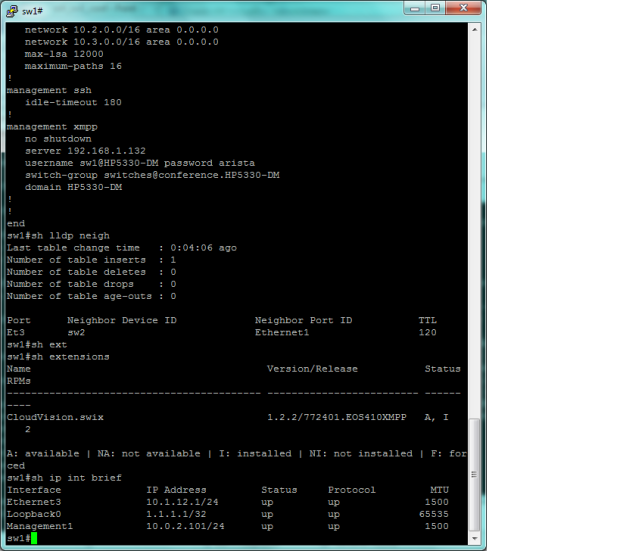
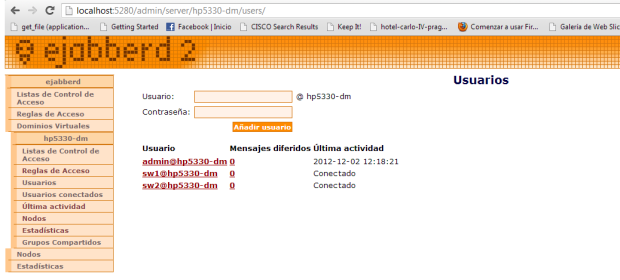
- Perfecto, ya tenemos el entorno virtual con vEOS, el cliente XMPP de CloudVision instalado en 2 equipos, y ahora, sólo queda instalar el servidor Jabber, donde definiremos estos usuarios sw1 y sw2. Esto lo he realizado fácilmente con ejabberd para Windows ;):
- Finalmente, para rizar el rizo, un último detalle para acabar el Lab: al igual que se puede gestionar vía el chat xmpp con cualquier cliente Jabber desde mi portátil, por que no hacerlo también desde el móvil? Voilà! Fácil: me da igual desde donde sea, desde mi portátil, desde mi iphone…puedo fácilmente gestionar desde 2 (los de este lab) hasta miles y miles de dispositivos Arista, mediante standards; que ya están diseñados para ser seguros y ligeros, multitenancy, y con la misma filosofía que el típico cliente de chat, pero en el que, ademas de lo que seria habitual, interactuamos para gestión y monitorización con nuestros equipos:
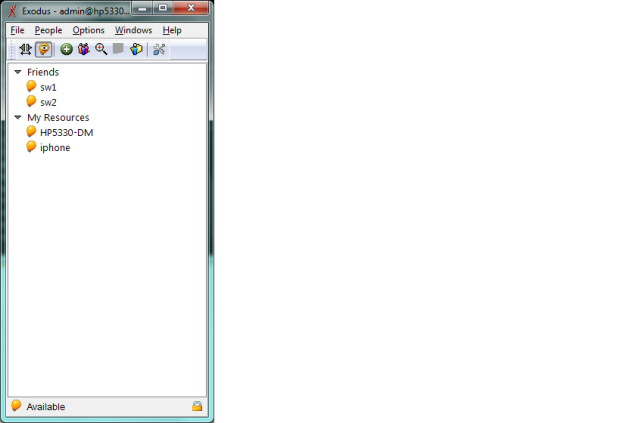
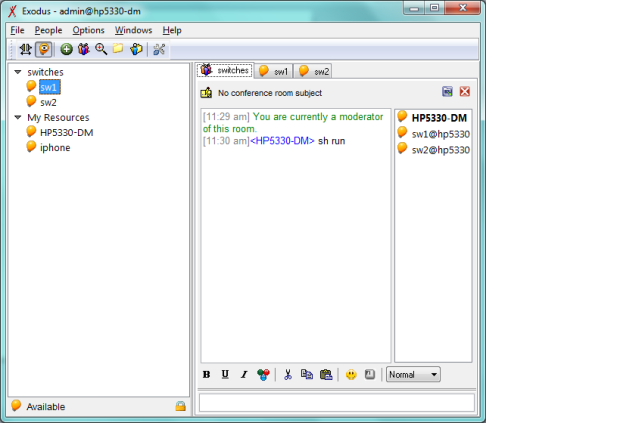
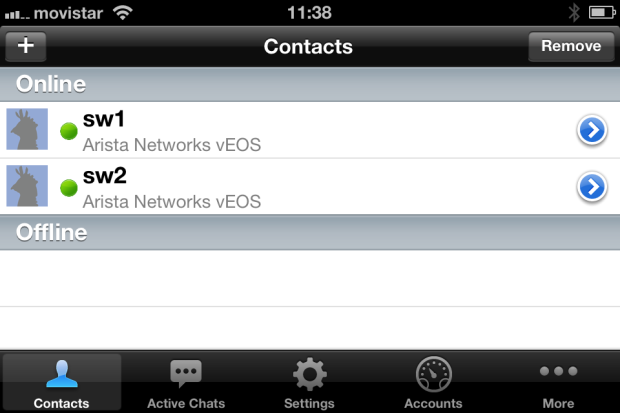
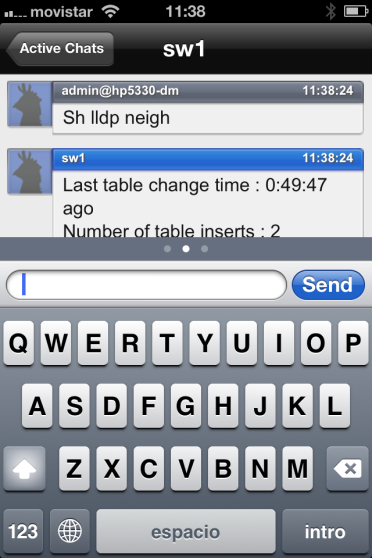
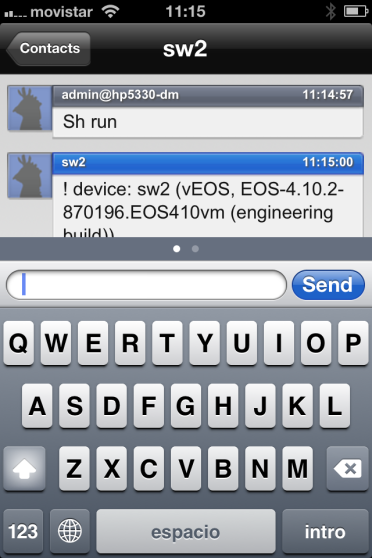
Resumen de articulos publicados – Arista Networks
Publicado por davidmacia en Arista, personal el 3 julio, 2012
Como hace algún tiempo ya que no publico nada en este blog, pero he ido generando diferentes artículos que han aparecido en prensa digital especializada, aprovecho este post para publicar una especie de bibliografia (corta por el momento) de mis aportaciones:
http://www.datacenterdynamics.es/focus/archive/2012/05/redes-40-gbe-como-respaldo-la-nube
http://www.datacenterdynamics.es/focus/archive/2012/06/redes-40-gbe-como-respaldo-la-nube-y-ii
Espero ser mas prolífico en el futuro, y como siempre, cualquier comentario será bienvenido!
saludos!
PALO ALTO NETWORKS: YA SOMOS LÍDERES EN EL GARTNER 2011!!
Publicado por davidmacia en Palo Alto Networks el 15 diciembre, 2011
- Diseño del NGFW (Next Generation Firewall).
- Capacidad de reorientar el mercado hacia el NGFW.
- Desplaçamiento constante del resto del mercado hacia lo que Palo Alto hace.
- Capacidad de disruptir en el mercado, obligando a los antaños líderes a reaccionar.
Gartner ha decidido reconocer todo este enorme mérito, y poner Palo Alto, que sacó el primer appliance en 2007, a ser líder ya en el 2011!!

Felicidades PAN!!
Innovación REAL, esta vez en Switching: Arista Networks
Publicado por davidmacia en Arista el 8 diciembre, 2011
Me gusta la innovación, supongo que es algo que los que lean algunos posts que he ido publicando habrán notado. En este blog, que no son nada mas que reflexiones relacionadas con mi dia a dia profesional, pero desde un punto de vista mas libre y directo, me gusta tratar aquellas soluciones que en mi punto de vista aportan, a través de la innovación, un plus muy interesante de valor añadido y mejora por tanto para las empresas. Hoy toca hablar de switching:
Cuando pensamos en switching, nos viene a la cabeza la idea de un equipo que es ya, como concepto, y en antagonismo con la innovación, una «commoditie». No me entendais mal, no es el que no tengan su complejidad y funcionalidades, pero a nivel genérico, un switch tradicional no es mas que un equipo que conmuta los paquetes de información entre sus puertos, lo mas rápido que puede. Con switch, asocias palabras como STP, VLANs, nivel 3, nivel 2, ACLs, QoS,…:Ok, hace unos años, esto era en la mayoria de casos mas que suficiente. En entornos grandes, hacías la típica arquitectura de Cisco de Core-distribución-acceso, Vlans, STP, y pim pam!
Las necesidades han ido evolucionado: cada vez mas (y precisamente es el sector donde hay mas crecimiento dentro del mercado del switching) vamos a 10 GbE; tenemos entornos virtuales, tenemos un flujo de tráfico que no se parece en nada al vertical (norte – sur = LAN – WAN), sinó que es mas horizontal (Este-Oeste = Interno, entre clusters de servidores)…Delante estos requerimientos de mas y mas tráfico, HPC (High-Performance Computing), Cloud Computing, SAN, etc, el concepto que se asumía antaño de tener sobresubscripción (básicamente, que si todos los usuarios de todos los puertos del switch transmiten datos en su máximo nivel, el equipo no tendrá suficiente capacidad de procesado, y por tanto, a nivel práctico, su rendimiento se degrada), es algo que no nos podemos permitir. Cada vez mas, la velocidad es dinero, y poder disponer de equipos con la mas baja latencia del mercado es algo a considerar, y el caso mas extremo podria ser el de HFT (High Frecuency Trading), donde milesimas de segundo significan miles de transacciones económicas.
En el seminario que hicimos hace unos dias con mis compañeros de Exclusive Networks (por cierto, Prezi es una manera genial de contar historias, nunca mas aburridas PPTs ;)), planteabamos precisamente estas y otras problemáticas, como:

Como lo solucionamos? cual es la innovación REAL en switching de Data Center? Arista Networks. Son equipos sin sobresubscripción, con el mas bajo consumo eléctrico por puerto, con la mas baja latencia del mercado (< 500 ns!!!), y el único (por poner un ejemplo), con tener en 1 chasis, 384 puertos a 10 GbE sin sobresubscripción, en un equipo de 11 U…BRUTAL!


Ademas de todo esto, si dejamos de lado el hardware (todos los modelos son totalmente redundados N+1) y su arquitectura, ASICs, etc, hay aun mas: su sistema operativo de red. Se llama EOS: totalmente modular, robusto, y sin perdida de servicio en ningun proceso, ya que todos ellos son independientes, gestionados por el Process Manager, y donde su estado es guardado en el SysDB. Si cae cualquiera de estos procesos, y sin afectar al resto, el ProcManager crea un proceso igual, y el SysDB vuelca en él el estado del anterior proceso, con lo que no hay corte. Traducción: de lo que se enterará el administrador de redes es, a lo sumo, de que hay alarmas de down/up de procesos (OSPF, SNMP, etc), pero NO a nivel de servicio.
El EOS no es nada mas que un Linux Fedora, muy pensado y elaborado, cerrado en su nucleo principal de funciones de red, pero abierto a terceros paquetes de software…¿que significa esto? Como muestra un boton: Puedo estar administrando mi Arista en el CLI normal, con los comandos habituales de red, y si quiero, accedo a la bash del sistema, donde facilmente utilizaré los comandos de Linux, o instalo otros paquetes que me puedan ser aun mas interesantes y utiles para dar valor a mi red.

Una vez en la Bash, imaginación al poder, como hacer un ifconfig -a, y luego un tcpdump para troubleshooting:
ifconfig -a
cpu Link encap:Ethernet HWaddr 00:1C:73:13:73:E0
UP BROADCAST RUNNING MULTICAST MTU:9216 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
et1 Link encap:Ethernet HWaddr 00:1C:73:13:73:E0
UP BROADCAST MULTICAST MTU:9212 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
et2 Link encap:Ethernet HWaddr 00:1C:73:13:73:E0
UP BROADCAST MULTICAST MTU:9212 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
et3 Link encap:Ethernet HWaddr 00:1C:73:13:73:E0
UP BROADCAST MULTICAST MTU:9212 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
et4 Link encap:Ethernet HWaddr 00:1C:73:13:73:E0
UP BROADCAST MULTICAST MTU:9212 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
et5 Link encap:Ethernet HWaddr 00:1C:73:13:73:E0
UP BROADCAST MULTICAST MTU:9212 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX ^C
[admin@localhost ~]$ tcpdump -i et2
tcpdump: WARNING: et2: no IPv4 address assigned
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on et2, link-type EN10MB (Ethernet), capture size 65535 bytes
Si imaginamos mas, podemos poner en el EOS, un Nagios, un MRTG, un Puppet, Cacti, máquinas virtuales con KVM…uff!!!
Con Arista, desaparecen de un plumazo también los siguientes problemas:
- Virtualización: Se enlaza, mediante su funcionalidad VMTRACER, con la API del VCenter de VMWARE, para tener visibilidad y control de el entorno virtualizado de cualquier empresa, y asegurar que delante cualquier cambio de configuración, añadidos, problemas, etc, la red será consciente de ello y modificará su configuración automáticamente para adaptarse a ello.
- Spanning-Tree: Desaparece, con la funcionalidad MLAG que tienen TODOS los modelos, y que básicamente lo que permite es agregar pares de equipos Arista en una única entidad lógica, y permitir la agregación de enlaces de otros Arista que cuelguen de ellos, hasta 16 puertos cada uno, y por tanto; 2x16x10 GbE = 320 Gbps de uplink sin pestañear, y sin desperdiciar, como se hacia en STP, la mitad de los enlaces entre equipos.
Resumiendo: lo que será futuro en Switching de elevadas prestaciones en unos años, lo tenemos ahora con Arista. Esto es innovación.
Corazón de manzana
Publicado por davidmacia en Sin categoría el 28 agosto, 2011
Hace varios días nos hemos enterado todos del cese de Steve Jobs como CEO de Apple, y muchos especulan que es debido a una larga enfermedad en la que lleva tiempo luchando. Esta noticia me ha hecho reflexionar sobre mi relación con Apple, con cierta nostalgia.
Con 9 años, mi padre dejó su trabajo fijo y estable como jefe de laboratorio para emprender la aventura empresarial de montar una tienda de informática, cuando en la informática se hablaban de casetes, BASIC, Pac-Man como juego estrella, memorias de 16KB, etc, y además en una nueva ciudad!. No sólo daban formación, con unos Spectrum de 16KB, con teclas de goma, con televisor como monitor (qué tiempos aquellos), sinó que empezaban a vender unos ordenadores llamados Apple II.

Al cabo de poco, aparecieron los Macintosh, (por supuesto dado el trabajo de mi padre, fuimos de los primeros en España en tener uno), y aun me acuerdo como me explicaba que este equipo marcaba un antes y un después: mouse, entorno gráfico, mucho mas potente,…flipaba con el editor de textos, los dibujos que se podian hacer con el mouse, la facilidad de uso…Iba entonces al cole con mi camiseta Apple, intentando evangelizar a mis amigos, totalmente motivado, pero en esa época (y durante mucho tiempo), Apple era muy de nicho: los niños tenian un Commodore 64, Amstrad, Amiga, y no estaban para oir las historias de un niño que les hablaba de Jobs, de su Mac, o de cuando Steve fichó al CEO de Pepsi para dirigir a Apple, y este lo despidió. Eso sí, no salian de su asombro con mis trabajos: ellos con su editor de textos cutre MSDOS (o mas adelante del Windows 3) estaban a años luz de mi Mac.
Siempre me pareció muy injusto que Microsoft copiase con su sistema operativo Windows el concepto del Mac. Como copia mala además («si lo hubiesen patentado…», pensaba). Y que gracias a ello y a un Marketing brutal consiguiesen ser los reyes de la microinformática. No sabía que no sólo se gana por tener un mejor producto, sinó que influyen muchas mas cosas.
Después Steve volvió, y bueno, todo el mundo sabe la historia, el discurso de Stanford, y Apple desde luego ya no es un producto nicho, ni está en desventaja frente a los grandes, porque es la más grande ahora.

Viendo su historia, que es la de Jobs, es cuando uno ve que la innovación y la visión es lo que hace a una compañia marcar la diferencia.
Cuando era pequeño, ir con Apple era para mi una forma de acentuar mi rebeldía al Status Quo, y se quedó allí, en mi corazón, un poco de la Manzana, para siempre.
El tiempo ha dado la razón a Jobs y su visión, creando en sus millones de compradores, ese mismo sentimiento de pertenencia a algo diferente, a tener también un cachito de esa manzana que Jobs y Wozniak sembraron en un garaje allá por el 76.
Talento TIC
Publicado por davidmacia en Palo Alto Networks, personal, Sin categoría el 15 abril, 2011
Llevaba tiempo pensando en dedicar una entrada de este blog para hacer un pequeño homenaje. Los americanos lo hacen muy bien: a quien vale, lo promocionan, sale en los medios, le hacen entrevistas, escriben libros…se vuelve una estrella, cosa que también sucede dentro del mundo IT. Aquí en España hay muchos casos de gente muy válida, que hace grandes cosas, pero digamos que la repercusión de ello es a otra escala. Aquí va mi granito de arena: Felicidades, Albert!!
Albert creyó en una idea, en un producto de seguridad que sabia que revolucionaria el mercado: Palo Alto Networks, y ha sido fiel a esa idea desde el principio. Además, supo prever que habría necesidad: Poder migrar las políticas de seguridad de los demás Firewalls, a Palo Alto…consecuencia: Albert creó la herramienta de migración que da gratis a los partners, para ayudarles en las masivas migraciones de políticas que tienen que afrontar…y Albert trabaja ahora en PAN: Sueño cumplido!
La herramienta, muy útil para los partners de Palo Alto que tienen que realizar migraciones de firewalls de otros fabricantes, es extremadamente ágil, intuitiva, i reduce drásticamente los tiempos del equipo técnico encargado del proyecto de migración…y lo mejor: gratis para los partners certificados!
Como muestra, un botón:


Changes
Publicado por davidmacia en personal el 31 marzo, 2011
…pues eso, changes ;)…la vida es eso: cambios, cambios constantes, cambios pequeños, o significativamente grandes. En esta ocasión (permitidme darle a este un blog una entrada mas personal ;)), un cambio de rumbo a nivel laboral. En mi perfil linkedin (http://www.linkedin.com/in/macia) veréis en breve una nueva entrada. Deciros que afronto el cambio con muchas ganas, optimismo, y como un reto muy atractivo (el mejor hasta ahora).
Me encanta el discurso (como a muchos), de Steve Jobs en la Stanford. Sobre como habla de que los puntos se unen, mirando hacia atras, al pasado, y que al mirar hacia adelante, hay que guiarse, con determinación, por la intuición, y el corazón. Creo firmemente en ello, y a ello voy…deseadme suerte!!
SPLUNK & PALO ALTO: VISIBILIDAD TOTAL + REPORTING “AD INFINITUM”
Publicado por davidmacia en Palo Alto Networks, splunk el 23 marzo, 2011
De siempre, en las grandes corporaciones, tener guardados los logs de los activos de red, seguridad, sistemas, etc, es una necesidad. Hay empresas que simplemente los guardan por temas de normativas de seguridad, y cuando les es necesario investigar sobre cualquier incidencia o necesidad de reporting “a posteriori”, se procede a analizar su contenido, y/o realizar reportings, que suelen ser complejos, debido a la gran cantidad de información a tratar, y poco eficientes, dado que el informe final no suele cumplir todas las necesidades de los responsables de redes o seguridad de estas empresas.
Hay otras empresas que quieren utilizar esta información, estos logs, para intentar ser mas proactivos, para poder tener una foto actual, e histórica, del estado de sus comunicaciones, y poder prever su tendencia futura, así como detectar sus problemas en tiempo real.
Para poder interpretar, y correlacionar toda esta información, la terminología que existe en los mercados se denomina SIEM (Security Information and Event Management).
A diferencia de la mayoría de fabricantes de estos productos, Splunk no requiere una capa de traducción de la información entrante hasta una taxonomía propietaria, ahorrando el enorme esfuerzo de desarrollo de esos archivos de mapeo y del mantenimiento de firmas de reconocimiento de dispositivos.
A modo resumen, pues, e introduciendo un SIEM de elevado valor añadido: Las grandes ventajas competitivas de Splunk son, por un lado, su capacidad de asimilar en tiempo real grandes volúmenes de información de todo tipo de dispositivos y sin necesidad de agentes «traductores»; y, por otro lado, su potente buscador, que permite la investigación de incidencias y análisis forense.

Por otra parte, el otro actor en este post, Palo Alto Networks: Ya he hablado de este revolucionario Firewall (https://pensandoentic.wordpress.com/2010/10/24/palo-alto-networks-it%E2%80%99s-time-to-fix-the-firewall/). Uno de sus puntos fuertes es su capacidad de monitorización y reporting, y dado que lo hace sobre lo que controla, que es el análisis y detección de las aplicaciones que circulan por la red, esta monitorización es mucho más interesante e útil, dado que la información que se extrae de ella: Aplicaciones, riesgo asociado a ellas, amenazas, ataques, malware, usuarios, categorización de webs…
Vale, entonces, tenemos: Splunk, que indexa cualquier log, y Palo Alto, que como firewall de nueva generación con una potente plataforma de gestión incorporada, da una visibilidad sin precedentes….Que pasa si unimos los dos? Y por qué? Podríamos pensar que con Palo Alto ya tenemos bastante, y así es….pero, qué pasa con esa necesidad de guardar los logs, durante por ejemplo 1 año? Y si queremos ver tendencias, analizar el comportamiento de mi red, cumplir normativas, etc, y lo queremos además de forma muy rápida, distribuida si es necesario, y montar al final un cuadro de mandos totalmente personalizado, de todos los logs…”ad infinitum”? y además, orientado a aplicaciones, usuarios, amenazas….información útil!
Como muestra un botón, simple pero efectivo: Sólo tenemos que configurar el envio de logs via syslog en el Palo Alto, hacia Splunk (escuchando el puerto syslog), y:
1) Realizando una búsqueda de todos los logs relacionados con nuestro Palo Alto, saca un listado de los mismos, con todos los campos que ha encontrado.

2) No sólo los campos mas utilizados, sino todos los campos que detecta del log, que no son pocos. A partir de ahí, se pueden ver ciertas estadísticas sobre los mismos, y lanzar un report (y parametrizarlo).

3) De todos los campos que interesen, se van creando reports, y añadiéndolo a un Cuadro de Mandos personalizado, con aquella información que nos interese controlar. Y al final, podemos tener algo como esto, de manera rapida y efectiva, totalmente indexado, escalable, y por un periodo de tiempo todo lo largo que queramos:


Espero que os haya resultado interesante 😉
 Suscríbete por RSS
Suscríbete por RSS- Análisis, informes, datasheets…hay que leer la letra pequeña!
- PALO ALTO NETWORKS: EL TIEMPO NOS DA LA RAZÓN
- Arista Networks, Laboratorio: vEOS y CloudVision para empezar a jugar
- Resumen de articulos publicados – Arista Networks
- PALO ALTO NETWORKS: YA SOMOS LÍDERES EN EL GARTNER 2011!!
- Innovación REAL, esta vez en Switching: Arista Networks
- Corazón de manzana
- Talento TIC
- Changes
- SPLUNK & PALO ALTO: VISIBILIDAD TOTAL + REPORTING “AD INFINITUM”
- Blog que sigo: Robclav
- Se ha producido un error; es probable que la fuente esté fuera de servicio. Vuelve a intentarlo más tarde.
- Juniper Networks – The Network Ahead
- Se ha producido un error; es probable que la fuente esté fuera de servicio. Vuelve a intentarlo más tarde.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Debe estar conectado para enviar un comentario.